LightRAG:生产环境部署实战——从 Demo 到线上可用(八)
走到第八篇了。前面七篇我们把 LightRAG 从原理到管线、从检索到索引、从存储到全链路都拆透了。这一篇换个角度——如果要把它从 demo 推到线上,到底该怎么落地。
笔记本上 pip install + 跑 demo 是一回事,生产上线又是另一回事。这一篇就讲讲两者之间那道沟里都藏着什么。
一、笔记本跑得好好的,为什么上线就跪了
LightRAG 本地跑通并不难,真正容易出问题的是规模一上来之后的工程细节。常见路径基本长这样:
- 第一周:本地 JSON 后端跑得飞起,效果很惊艳。
- 第二周:放到测试环境,灌进真实业务数据(几十万文档),开始 OOM、API 限流、索引跑半天没动静。
- 第三周:手忙脚乱换 PostgreSQL、调 max_async、加 reranker、套 nginx、配监控……
- 第四周:系统终于稳了,才发现一开始就该按生产标准设计。
省事的做法是反过来:一开始就按生产假设搭,再回到笔记本上简化。下面按部署、存储、模型、性能、可观测、安全六块讲。
二、部署方式怎么选
LightRAG 仓库现在提供了几条部署路径,从轻到重可以这样选:
1. pip 直接装(Server 模式)
1
2
3
4
uv tool install "lightrag-hku[api]"
# 或:pip install "lightrag-hku[api]"
# 准备 env.example/.env,并配置 LLM、embedding、reranker
lightrag-server
适合:个人项目、内部小工具、单机 PoC。优点是启动快,缺点是存储、并发、鉴权、备份这些事情都要自己补齐,不能把“跑起来”误当成“可上线”。
2. Docker Compose(推荐)
仓库根目录有两个 compose 文件:
docker-compose.yml:单服务,只起 LightRAG,存储用本地卷。docker-compose-full.yml:全套,把 PostgreSQL(pgvector)、Neo4j、Milvus、vLLM(embedding + reranker)都拉起来。这份配置里 LightRAG 已经按服务名连各个后端(POSTGRES_HOST: postgres、NEO4J_URI: neo4j://neo4j:7687、MILVUS_URI: http://milvus:19530),改改密码就能跑。
如果不想手改 .env,仓库提供了交互式 setup wizard:
1
2
3
4
make env-base # LLM、embedding、reranker
make env-storage # 存储后端和数据库服务
make env-server # 服务端口、鉴权、SSL
make env-security-check # 上线前检查安全配置
它会按你的选择生成 .env,需要 Docker 服务时也会生成 docker-compose.final.yml。比手撸 yaml 友好得多,详见 docs/InteractiveSetup.md。
3. Kubernetes(Helm Chart)
k8s-deploy/ 下提供了 Helm chart 和一键脚本:
1
2
3
4
5
# 轻量部署(用内置存储,测试用)
bash ./install_lightrag_dev.sh
# 生产部署(外接 Postgres + Neo4j)
bash ./install_lightrag.sh
适合:已经在 K8s 上的团队、需要多副本和滚动升级。Helm values 里把所有 env 都暴露出来了,按 k8s-deploy/lightrag/values.yaml 改。
4. 离线部署
如果你的服务器没有公网(金融、政府、内网客户),docs/OfflineDeployment.md 详细讲了怎么打离线包。Docker 镜像本身已经预装离线运行所需的常见依赖;如果走 pip/venv,核心思路是提前把依赖和 tiktoken cache 都准备好:
1
2
3
4
5
6
# 在联网环境
pip install lightrag-hku[offline]
lightrag-download-cache # 把 tiktoken 模型下载到本地
pip download lightrag-hku[offline] -d ./offline-packages
tar -czf lightrag-offline.tar.gz ./offline-packages ~/.tiktoken_cache
# 带到离线环境后,用 pip install --no-index --find-links= 安装
注意 LightRAG 用 pipmaster 做动态依赖安装(用到哪个存储后端就装哪个),离线必须提前把所有可能用到的包都下好,否则跑起来会突然报缺包。
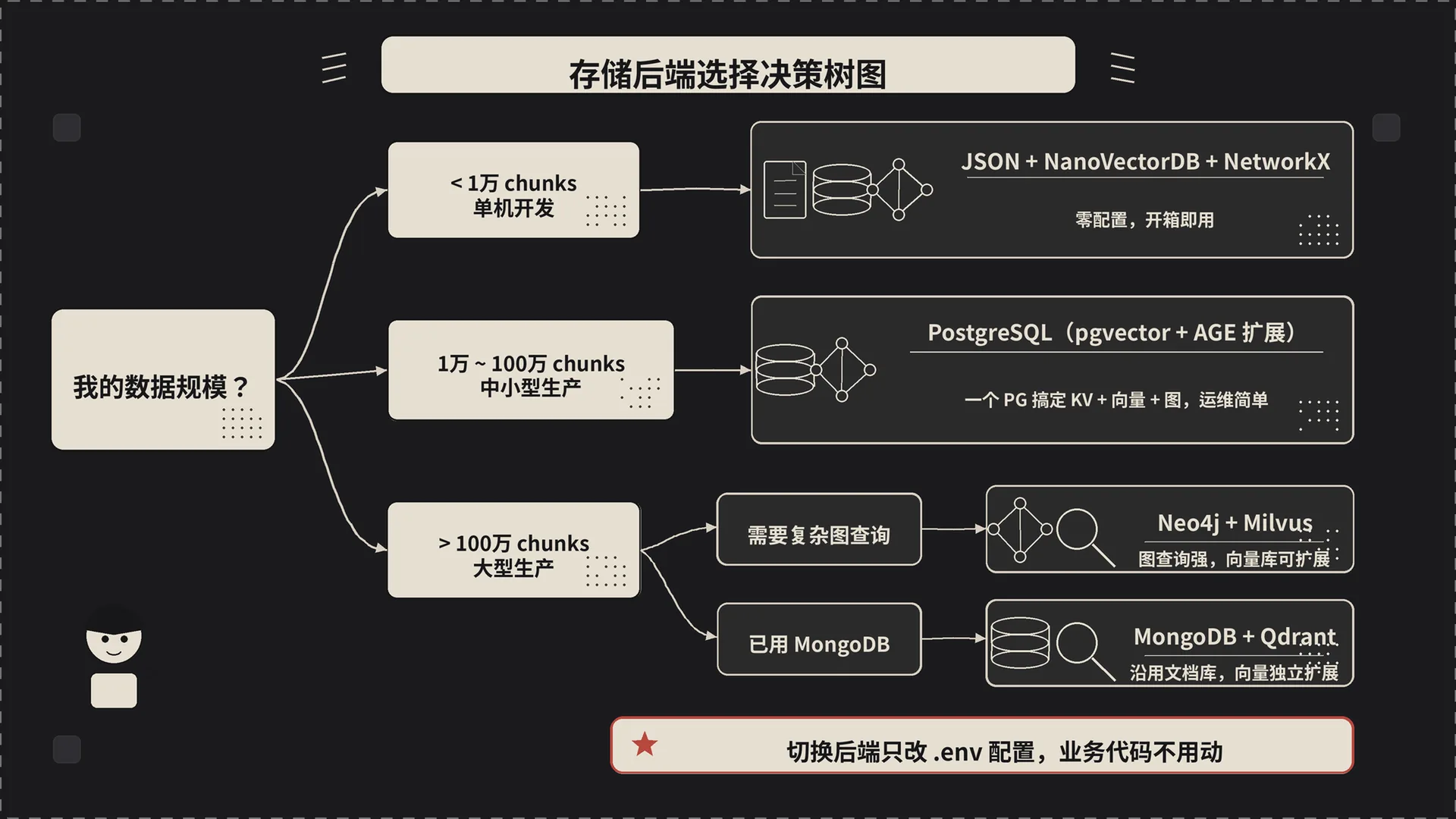
三、存储后端选择——最重要的决策
三档规模(JSON / PostgreSQL 一把梭 / Neo4j+Milvus 分层)的取舍第 5 篇已经摊开讲过。这里只补一种生产里非常常用的混搭组合:
1
2
3
4
LIGHTRAG_KV_STORAGE=MongoKVStorage
LIGHTRAG_VECTOR_STORAGE=MilvusVectorDBStorage
LIGHTRAG_GRAPH_STORAGE=Neo4JStorage
LIGHTRAG_DOC_STATUS_STORAGE=MongoDocStatusStorage
KV / 状态走 MongoDB(文档型存储 + 现成的 schema 灵活性),向量走 Milvus(专业活让专业的干),图走 Neo4j(Cypher 查询能力是 PG 比不上的)。三家各干各的,不互相牵制。代价是要维护三套基础设施——团队规模够、运维带得动再上。
切换存储不需要改业务代码,.env 改完重启就行。
四、模型选型——别在小钱上栽大跟头
模型选型的基本原则(索引模型要足够会抽实体关系、查询模型可以更强、embedding 选定后不要轻易换、reranker 别省)第 2 篇已经讲过。生产环境里不要只看单价,要按 索引成本 + 查询成本 + 运维成本 + 重建成本 一起算。
一份真实报价表很快会过期,更稳的估算方式是把成本拆成四项:
| 成本项 | 主要受什么影响 | 生产建议 |
|---|---|---|
| 首次索引 | 文档量、chunk 数、抽取模型单价、MAX_ASYNC | 先用 1%-5% 样本估算 token,再外推全量 |
| 增量索引 | 每日新增文档、实体合并复杂度、缓存命中率 | 开启抽取缓存,保留 doc status,避免失败后全量重跑 |
| 查询 | QPS、上下文长度、查询模型、reranker 调用 | 不要盲目拉大 MAX_TOTAL_TOKENS,先让 reranker 把噪声砍掉 |
| 运维 | GPU/数据库/备份/监控/值班 | 小团队先用 API + 托管数据库,大规模稳定后再考虑自部署 |
几个经验值得留意:
- 索引和查询可以分模型:索引用性价比高、结构抽取稳定的模型;查询用更强的模型。
QueryParam(model_func=...)可以按请求切换。 - 本地 vLLM 不等于免费:GPU 服务器、显存余量、升级、监控、值班都算钱。量不够大时,API 往往更省心。
- embedding 维度是长期决策:PostgreSQL、Milvus 这类后端建表/建索引时会绑定向量维度,换 embedding 常常意味着重建向量索引。
- Reranker 单独算账:它增加一次调用成本,但能显著减少无效 chunk 进入最终 prompt。生产环境里通常比“给 LLM 塞更多上下文”更划算。
五、性能调优——把每个旋钮拧到位
env.example 里有几十个可调参数,绝大部分用默认就行。真正需要调的就这几个:
并发控制
1
2
MAX_ASYNC=4 # 单个 chunk 抽取的 LLM 并发上限
MAX_PARALLEL_INSERT=2 # 同时处理几个 doc
MAX_ASYNC 是 LightRAG 整个调优最关键的一个。默认 4 太保守,OpenAI/DeepSeek 这种成熟 API 调到 16 / 32 都没问题。本地 vLLM 调到 64 也行(取决于显存)。
但别盲目调大:
- 触发上游 rate limit 反而更慢
- 内存压力变大(每个并发的 prompt + response 都在内存里)
- 出错时调试更难(多个并发请求的 log 交叉)
chunk 参数
1
2
CHUNK_SIZE=1200 # 单个 chunk 的 token 数
CHUNK_OVERLAP_SIZE=100 # 相邻 chunk 重叠
中文场景这俩可以适当调大(CHUNK_SIZE=1600、CHUNK_OVERLAP=150),因为中文一个 token 信息密度比英文高、句子也更长。技术文档类语料尤其需要大 chunk。
检索参数
1
2
3
4
5
6
TOP_K=40 # local/global 各自的实体/关系召回数
CHUNK_TOP_K=20 # rerank 后保留的 chunk 数
RELATED_CHUNK_NUMBER=5 # 每个实体最多关联多少 chunk
MAX_TOTAL_TOKENS=30000 # 总上下文预算
COSINE_THRESHOLD=0.2 # 向量相似度过滤阈值
MIN_RERANK_SCORE=0.0 # reranker 分数下限
MAX_TOTAL_TOKENS 是按你查询 LLM 的上下文来调的。但不一定越大越好——多塞的 chunk 如果 reranker 没顶住,就是噪声。
MIN_RERANK_SCORE 建议设到 0.3-0.5。砍掉低分 chunk 比堆量更有效。
缓存
1
2
ENABLE_LLM_CACHE=true # 总开关
ENABLE_LLM_CACHE_FOR_EXTRACT=true # 索引阶段缓存
线上这两个一定开。索引缓存能让重建、改 prompt、换 embedding 的代价直接降到几乎为零。
六、可观测性——出问题之前你得能看见
LightRAG 自带的 log 已经不错(每个 chunk 的抽取、每条 query 的检索都打 log),但生产环境光看 log 不够。
Langfuse 接入
Langfuse 是 LLM 应用的 trace + 评估平台,开源、可自部署。当前 LightRAG 已经提供 observability extras,OpenAI-compatible 调用可以直接接入:
1
2
3
4
5
6
pip install "lightrag-hku[observability]"
LANGFUSE_SECRET_KEY=...
LANGFUSE_PUBLIC_KEY=...
LANGFUSE_HOST=https://cloud.langfuse.com
LANGFUSE_ENABLE_TRACE=true
接上之后能在 Langfuse 看板看到:每个 query 走了几轮 LLM、每轮耗时多久、token 花在哪。注意它当前主要覆盖 OpenAI-compatible 调用,Ollama、Azure、Bedrock 这类路径要看官方文档支持状态。
RAGAS 评估
RAGAS 是评估 RAG 质量的常用工具。从 faithfulness(回答忠实度)、answer_relevancy(相关性)、context_precision/recall 等维度量化。LightRAG 现在也提供了基于 RAGAS 的评估脚本。
线下定期跑评估集,能在改 prompt / 换模型 / 调参数后立刻看到是变好了还是变差了。没评估指标盲调,是 RAG 项目最大的坑。
日志聚合
LightRAG 输出标准 Python logging,对接 Loki / ELK / Datadog 都很顺。重点关注几个 log:
Chunk N of M extracted X Ent + Y Rel:索引进度Round-robin merged chunks: X -> Y:检索去重情况Token allocation - Total: ... Available for chunks: ...:动态预算分配Final chunks S+F/O: E5/2 R2/1 C1/1:最终 chunk 的来源追踪(E=entity、R=relation、C=vector)
最后这条 S+F/O log 是调检索质量时的金矿——能看到答案到底是被 local / global / vector 哪一路救回来的。
七、安全配置——一份清单
1. API 鉴权(必做)
1
2
3
4
5
6
# .env 二选一
LIGHTRAG_API_KEY=your-secure-api-key-here
# 或者多账号
AUTH_ACCOUNTS='admin:admin123,user1:{bcrypt}$2b$12$...'
JWT_SECRET=your-jwt-secret
API Key 走 header X-API-Key,账号密码走 JWT。生产环境绝不要裸跑(默认是无鉴权)。
2. SSL/TLS
1
2
3
SSL=true
SSL_CERTFILE=/path/to/cert.pem
SSL_KEYFILE=/path/to/key.pem
或者前面套 nginx / Traefik 终结 TLS,LightRAG 跑 HTTP,更灵活。
3. Workspace 多租户隔离
1
2
3
WORKSPACE=tenant_a # 全局 workspace 名
# 或针对单个存储
POSTGRES_WORKSPACE=tenant_a
LightRAG 的 workspace 机制会给每个表 / 节点 / 向量加 workspace 前缀,做到完全的数据隔离。SaaS 模式下多租户必备。
4. PostgreSQL SSL
1
2
3
4
POSTGRES_SSL_MODE=require
POSTGRES_SSL_CERT=/path/to/client-cert.pem
POSTGRES_SSL_KEY=/path/to/client-key.pem
POSTGRES_SSL_ROOT_CERT=/path/to/ca-cert.pem
云数据库(RDS、Cloud SQL)一定开。本机 docker network 内部可以不开。
5. 速率限制
LightRAG 本身没做 rate limit。前面套 nginx / API Gateway / Cloudflare 来限。对查询接口按 IP / API Key 限流,对索引接口限并发上传。
6. 数据备份
- KV / Graph / Vector 三类存储分别按各自后端的备份方案。
- 特别提示:
kv_store_llm_response_cache.json(或 PG 里对应表)必须备份——这玩意是命根子,丢了重跑要重新花钱抽实体。
八、生产里几个最常见的坑
1. OOM
征兆:索引大语料时进程被 OOMKilled,或者查询时突然卡死。
根因 90% 是 NanoVectorDB 把整个向量库塞内存。
解法:换 PostgreSQL+pgvector 或 Milvus。docker-compose-full.yml 直接抄。
2. API rate limit / 502
征兆:索引到一半 LLM 报 429。
解法:
MAX_ASYNC调小- 上一层加 retry + exponential backoff(LightRAG 自带 tenacity 重试,但默认次数有限)
- 切到 DeepSeek 这种宽松的 API
- 实在不行就分批 insert,每批 500 doc
3. 索引慢到怀疑人生
先看 log 确认是抽取慢还是合并慢:
- 抽取慢 →
MAX_ASYNC调大、换更快的 LLM - 合并慢 →
summary_max_tokens调小、看是不是有某个实体被合并几百次(map-reduce 在递归)
4. 图谱”损坏”
征兆:查询突然返回空 / 报字段缺失。
解法(按代价从低到高):
- 先 backup 一份
kv_store_llm_response_cache.json - 删
vdb_*和graph_*,重跑——LLM 抽取全走缓存,几分钟搞定 - 还不行就重跑 ainsert,cache 兜底
5. 中文实体抽得乱
老话题:addon_params={"language": "Chinese"} 加上。没加这个参数中文场景效果腰斩,没有之一。
九、写在最后
这个系列从 RAG 的局限和 LightRAG 的设计动机开始,一路拆了查询管线、索引流程、存储架构、检索细节,到今天这篇生产实践——该看的源码和该踩的坑都过了一遍。
LightRAG 是个少见的学术想法落得扎实的开源项目。论文不长,但工程上花的功夫很密:prompt 缓存对齐 OpenAI 的前缀缓存、round-robin 合并、VECTOR/WEIGHT 双策略 fallback、map-reduce 的 summary、workspace 隔离。这些都不是炫技,是被真实场景逼出来的。
希望这个系列帮你少踩几个坑。
本文由 AgentPlanFlow 生成