LightRAG:文档是怎么变成知识图谱的——索引流程剖析(四)
第三篇我们把”查”这条路走完了。但还有一个绕不开的问题:那张被查询的知识图谱,到底是什么时候、怎么从一坨文本变出来的?
接下来我们一起看看 ainsert 内部,把这条索引流水线从头到尾拆一遍。
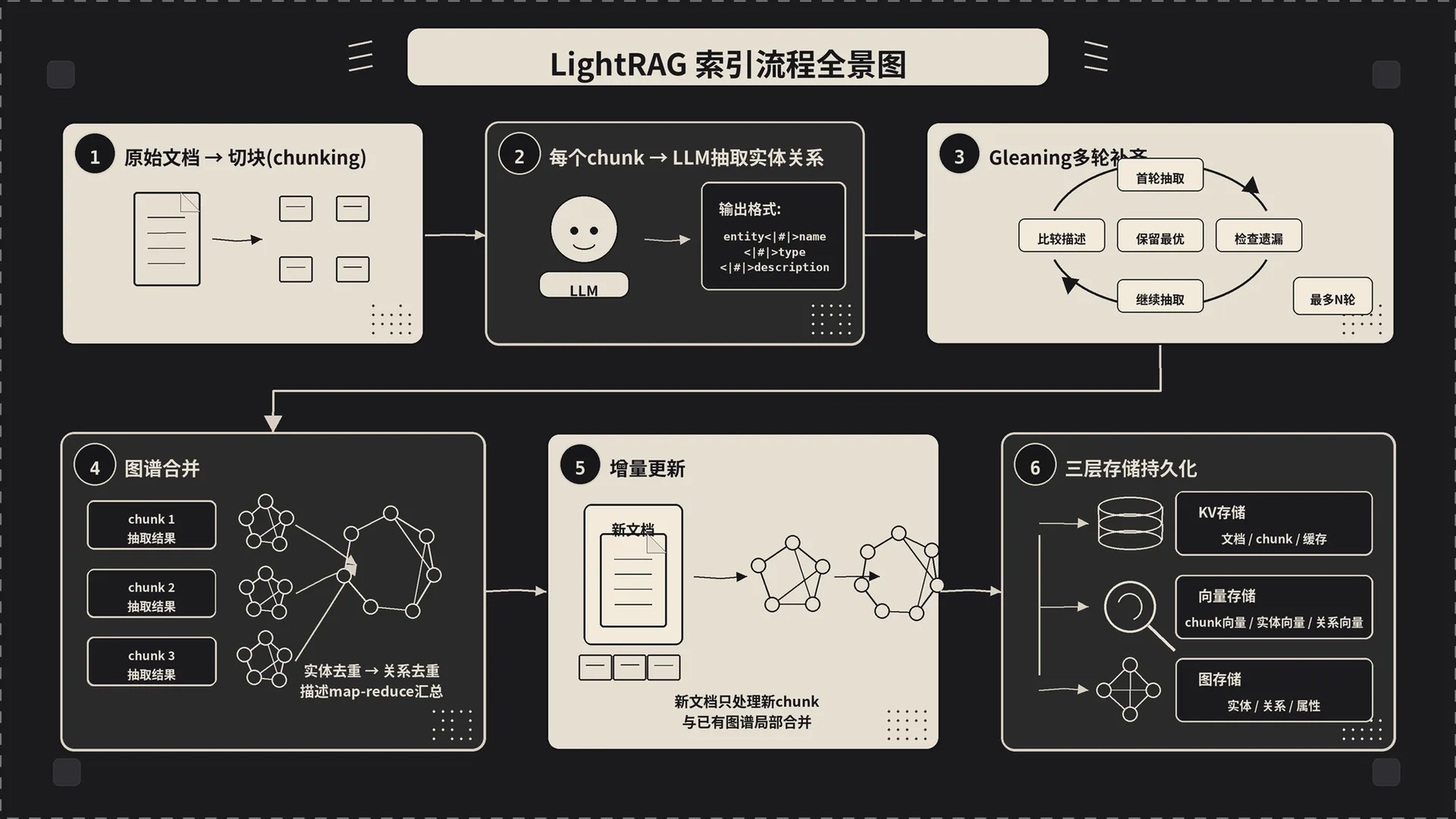
二、ainsert 的全貌——两阶段提交
入口在 lightrag/lightrag.py:1237:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
async def ainsert(
self,
input: str | list[str],
split_by_character: str | None = None,
split_by_character_only: bool = False,
ids: str | list[str] | None = None,
file_paths: str | list[str] | None = None,
track_id: str | None = None,
) -> str:
if track_id is None:
track_id = generate_track_id("insert")
await self.apipeline_enqueue_documents(input, ids, file_paths, track_id)
await self.apipeline_process_enqueue_documents(
split_by_character, split_by_character_only
)
return track_id
ainsert 本身没干啥重活,它只是把工作拆成两步:
- 入队:
apipeline_enqueue_documents(lightrag.py:1344)。把传进来的文档(不管是字符串还是字符串列表)算出 doc_id(MD5 hash 当默认 id)、写进 doc_status KV,标记成pending。这一步是同步的、轻量的,能在毫秒级返回。 - 出队执行:
apipeline_process_enqueue_documents(lightrag.py:1740)。从 pending 队列里拿文档,一篇一篇过流水线:切块 → 抽实体关系 → 合并入图 → 写存储。这一步重,长跑也在这里。
把”声明要插入”和”实际处理”切开的好处是:
- 调用方能立刻拿到
track_id,后续用这个 ID 查进度,不用阻塞等几小时。 - 进程挂了重启,pending 和 processing 状态会保留在 KV 里,下次自动续跑。
- 多篇文档可以排队、批处理、限流,避免并发把 LLM API 打挂。
接下来我们沿着 apipeline_process_enqueue_documents 里的核心三步走:切块、抽取、合并。
二、第一步:把文档切成 chunk
切块函数是可配置的(lightrag.py:328 的 chunking_func),默认实现是 chunking_by_token_size,源码在 lightrag/operate.py:101。
核心逻辑只有十来行:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def chunking_by_token_size(
tokenizer, content,
split_by_character=None, split_by_character_only=False,
chunk_overlap_token_size=100, chunk_token_size=1200,
) -> list[dict]:
tokens = tokenizer.encode(content)
results = []
# 默认走的是这条 else 分支:纯按 token 切
for index, start in enumerate(
range(0, len(tokens), chunk_token_size - chunk_overlap_token_size)
):
chunk_content = tokenizer.decode(tokens[start : start + chunk_token_size])
results.append({
"tokens": min(chunk_token_size, len(tokens) - start),
"content": chunk_content.strip(),
"chunk_order_index": index,
})
return results
几个关键参数:
chunk_token_size:默认 1200,是单个 chunk 的目标长度。chunk_overlap_token_size:默认 100,相邻两块之间的重叠 token 数。这个 overlap 看着浪费,其实非常重要——如果一句话刚好横跨两个 chunk 边界,没 overlap 的话两边都抽不全这条句子里的实体关系,加 100 token 的重叠等于给 LLM 留个”上下文喘息”的余地。split_by_character:如果你想优先按某个字符(比如\n\n段落分隔符)切,再在每段内部按 token 限制兜底,传这个参数。split_by_character_only:硬性按字符切,即便超出chunk_token_size也不再二次切——这会直接抛ChunkTokenLimitExceededError(见operate.py:123),所以一般用于”我已经预先按 Markdown 章节切好了”的场景。
注意 tokenizer 是按你配的 LLM 来的(tiktoken 默认用 gpt-4o 的编码器),不是按字符。中文文档实际切出来的字数会比 token 数多得多,建议不要调太小——中文文档 token 数远大于字数,太小的话一句话都切不完整。
切完之后每个 chunk 是一个字典:{tokens, content, chunk_order_index, full_doc_id, file_path, ...}。chunk_id 是按内容 hash 算出来的(chunk- 前缀 + MD5),同样的内容永远是同一个 chunk_id——这是后面缓存能命中的基础。
三、第二步:让 LLM 抽实体和关系
切完块之后,进入 extract_entities(lightrag/operate.py:2883),整个索引最耗时、最花钱的一步就是它。
3.1 prompt 长什么样
LightRAG 把抽取 prompt 拆成三段:
- system prompt——
entity_extraction_system_prompt(prompt.py:11)。这一段定义抽什么、怎么抽、用什么分隔符、用什么语言输出。 - user prompt——
entity_extraction_user_prompt(prompt.py:63)。把当前 chunk 的内容塞进去,触发抽取。 - gleaning user prompt——
entity_continue_extraction_user_prompt(prompt.py:84)。第二轮”补漏”用的,下一节细讲。
为什么 system 和 user 分开?源码注释(operate.py:2950)写得明白:
Format system prompt without input_text for each chunk (enables OpenAI prompt caching across chunks)
OpenAI 的 prompt caching 是按前缀匹配的。如果你每个 chunk 都把内容拼进 system prompt,那每个 chunk 的 system 都不一样,缓存命不中。把 system 固定下来(只放规则)、把内容塞到 user 里,OpenAI 就能把 system 那一大段命中缓存,省一大笔钱。
3.2 输出格式:自定义分隔符的妙处
很多人第一次看 LightRAG 的 prompt 会奇怪:为什么不让 LLM 输出 JSON?答案在分隔符的设计上。
prompt.py:8-9:
1
2
PROMPTS["DEFAULT_TUPLE_DELIMITER"] = "<|#|>"
PROMPTS["DEFAULT_COMPLETION_DELIMITER"] = "<|COMPLETE|>"
让 LLM 按这个格式输出:
1
2
3
4
entity<|#|>Scrooge<|#|>Person<|#|>A miserly old businessman in London...
entity<|#|>Tiny Tim<|#|>Person<|#|>The youngest son of Bob Cratchit...
relation<|#|>Scrooge<|#|>Bob Cratchit<|#|>employment,exploitation<|#|>Scrooge is Bob's employer...
<|COMPLETE|>
四段一个实体、五段一个关系,最后一个 <|COMPLETE|> 标志结束。这种”自定义带尖括号的分隔符”比 JSON 有几个实打实的优势:
- 不会被实体描述里的标点干扰。JSON 怕实体描述里的引号和花括号,要做转义;这种分隔符在自然语言里几乎不可能出现。
- 流式输出友好。一行解析一条记录,不需要等整个 JSON 闭合才能开始处理。
- LLM 输出稳定性高。LLM 输出 JSON 经常少个引号、多个逗号,定制分隔符的容错性强得多。
<|COMPLETE|>是显式终止符。LLM 因为 max_tokens 截断、还是真的抽完了,看这个标志一清二楚。
3.3 Gleaning:让 LLM 自己查漏补缺
这是 LightRAG 一个挺聪明的设计。配置 entity_extract_max_gleaning > 0(lightrag.py:289,默认就是 1),每个 chunk 会跑两轮:
- 首轮:跑标准的抽取 prompt。
- Gleaning 轮:把首轮的输出当 history,喂给 LLM,让它”看看刚才漏了啥”。
源码在 operate.py:2987 起:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
if entity_extract_max_gleaning > 0:
# 先检查 token 预算够不够
if token_count > max_input_tokens:
logger.warning(f"Gleaning stopped: input tokens exceeded limit")
else:
glean_result, timestamp = await use_llm_func_with_cache(
entity_continue_extraction_user_prompt,
...,
history_messages=history,
cache_type="extract",
)
glean_nodes, glean_edges = await _process_extraction_result(...)
# 合并:比较描述长度,留更长的那个
for entity_name, glean_entities in glean_nodes.items():
if entity_name in maybe_nodes:
original_desc_len = len(maybe_nodes[entity_name][0].get("description", ""))
glean_desc_len = len(glean_entities[0].get("description", ""))
if glean_desc_len > original_desc_len:
maybe_nodes[entity_name] = list(glean_entities)
else:
maybe_nodes[entity_name] = list(glean_entities)
合并规则有意思:同一个实体两轮都抽到了,留描述更长的那个——粗粒度地把”信息量更大”作为代理指标。新抽出来的实体或关系直接加进结果集。
为什么不是无限轮?因为收益递减得很快——首轮能抽出 80% 的实体,gleaning 一轮能再补 15%-20%,再多轮基本就在重复抽同样的东西、白烧钱。默认 1 轮 gleaning 是工程上比较甜的点。
3.4 LLM 缓存:换 embedding 也能省钱的关键
抽取这一步全程走 use_llm_func_with_cache。cache_type 是 "extract",cache key 是 (chunk_content_hash, prompt_hash, llm_model_name) 的组合。
也就是说:
- 同一个 chunk 内容 + 同一个 prompt + 同一个模型 = 命中缓存,不调 LLM
- chunk 内容改了 / prompt 改了 / 换模型了 = 重新调
这个缓存的实际意义:你删掉所有 vdb_*.json 想换 embedding 重建向量库时,LLM 抽取这一步全部命中缓存——重建只是重新算 embedding,没有任何 LLM 调用。一份大文档第一次跑可能花 $50,重建只要几毛钱的 embedding 成本。
并发控制在 extract_entities 末尾(operate.py:3093-3094):
1
2
chunk_max_async = global_config.get("llm_model_max_async", 4)
semaphore = asyncio.Semaphore(chunk_max_async)
max_async 同时控制多少个 chunk 在打 LLM。默认 4,调到 16 / 32 能显著加速,但小心 rate limit。
抽完之后,每个 chunk 吐出 (maybe_nodes, maybe_edges) 两个 dict:实体名/边 key → 实体或关系详情列表。注意是列表——同一个 chunk 里同一个实体可能被多次提及,gleaning 还会再补一遍,每次都追加一份。怎么合并是下一步的事。
四、第三步:把多个 chunk 的抽取结果合并成全局图谱
merge_nodes_and_edges 在 lightrag/operate.py:2501。它干的是两件事:把多个 chunk 的局部抽取合并成一个全局图,把合并结果同步进图存储、实体向量库、关系向量库。
源码注释(operate.py:2519)写得清楚:
1
2
3
4
Two-phase merge: process all entities first, then all relationships
1. Phase 1: Process all entities concurrently
2. Phase 2: Process all relationships concurrently (may add missing entities)
3. Phase 3: Update full_entities and full_relations storage with final results
4.1 实体合并
第一阶段,先把所有 chunk 的 maybe_nodes 收集到一个 defaultdict(list):
1
2
3
4
all_nodes = defaultdict(list)
for maybe_nodes, maybe_edges in chunk_results:
for entity_name, entities in maybe_nodes.items():
all_nodes[entity_name].extend(entities)
同一个实体名(按 title case 归一化过的)所有 chunk 的版本全聚到一起。然后并发处理每个实体名:拿到已有图里的旧版本(如果有),跟新一批合并,写回图存储和实体向量库。
合并的核心是处理”同一个实体被多次描述”的问题。”Scrooge” 在 30 个 chunk 里被提到,会有 30 段不同侧重的描述。LightRAG 的做法是把这些描述塞给 _handle_entity_relation_summary(operate.py:167)做 map-reduce 汇总:
- 全部描述加起来 token 不大、且数量不多(小于
force_llm_summary_on_merge)→ 直接separator.join,根本不调 LLM。 - 总 token 够小但描述数量多 → 让 LLM 一次性 summary。
- 总 token 超限 → 切成多组,每组单独 summary(map),再把这些 summary 合并(reduce),递归到结果够短为止。
这套 map-reduce 设计很关键,否则一个高频实体的描述会撑爆 LLM 的上下文。
边(关系)的合并同样套路,但 key 是 tuple(sorted([src, tgt]))——LightRAG 默认把图当成无向图,A→B 和 B→A 是同一条边。
4.2 为什么要”两阶段”
为什么必须先实体后关系?因为:
- 关系两端的实体必须已经在图里,否则关系会变成”悬空边”。
- LLM 抽出来的关系里偶尔会出现”在实体列表里没显式提到、但在关系里被引用”的实体。第二阶段处理关系时如果发现这种情况,会自动补回缺失的实体到图里。
- 把实体和关系分两阶段并发,能用
asyncio.Semaphore独立控制每阶段的并发度(graph_max_async = llm_model_max_async * 2,关系阶段并发更高)。
4.3 写向量库
合并完之后,每个实体/关系都会算 embedding 写进对应的向量库(entity_vdb / relationships_vdb)。embedding 输入是 "实体名: 描述" 或 "关系关键词: 关系描述",这是后面查询时 local / global 检索能命中的基础。
到这里,整个 ainsert 的核心三步走完。
五、增量更新:插一篇新文档,发生了什么
LightRAG 一个杀手锏是”增量更新不重建”。具体怎么做的?
新文档进来,走的还是 apipeline_enqueue_documents → apipeline_process_enqueue_documents。但因为:
- chunk 是按内容 hash 算 id 的,老文档已经有的 chunk_id 直接跳过(doc_status 标记成 processed)。
- 新 chunk 抽实体关系时,LLM 缓存能让”内容相同的 chunk”直接命中。
merge_nodes_and_edges处理实体时,会先knowledge_graph_inst.get_node(entity_name)把图里已有的旧版本拿出来,跟新一批一起做 map-reduce summary,再写回。
也就是说只对新 chunk 产生的新实体/新关系做增量合并,不碰其他已有节点。如果新文档里”Scrooge”被提到了,图里 Scrooge 节点的描述会被合并更新;如果新文档里没提到的实体,原封不动。
删除文档同理:找到这个 doc 关联的 chunks 和实体/关系(full_entities_storage 和 full_relations_storage 记录了这个 mapping),把这些 chunk 引用从实体的”出现 chunks 列表”里去掉。如果某个实体的引用 chunks 全空了,就把它从图里删掉。
这就是为什么 LightRAG 能在线上跑——增量更新不需要重建图谱,新文档只影响关联的局部节点。
六、三层存储干了什么
整个索引流程往三种存储里塞东西:
- KV 存储:
kv_store_full_docs(原文)、kv_store_text_chunks(切块结果)、kv_store_doc_status(每个 doc/chunk 的处理状态)、kv_store_llm_response_cache(LLM 调用缓存)。 - 向量存储:
vdb_chunks(chunk 向量)、vdb_entities(实体向量)、vdb_relationships(关系向量)。三套独立的 embedding 索引。 - 图存储:图节点(实体)、边(关系)、属性、邻接关系。GraphML / Neo4j / Memgraph 等。
每种存储都有自己的 base class(base.py 里的 BaseKVStorage / BaseVectorStorage / BaseGraphStorage),后端是可插拔的。从 JSON 文件切到 PostgreSQL 只是改配置,索引流程一行不用动——这是工程上做得最干净的一层。
七、缓存策略全景
索引这一头有三类缓存,搞清楚谁缓存谁能省下大笔时间和钱:
- LLM 抽取缓存(cache_type=”extract”):每个 chunk 的实体关系抽取结果。换 embedding 不会失效,改 prompt 会失效。
- LLM summary 缓存:
_handle_entity_relation_summary里调 LLM 做 map-reduce 也会过 cache。同一组描述只 summary 一次。 - Doc status:哪些 chunk 已经 processed、哪些还 pending。跑到一半挂了,重启会从 pending 的继续,已 processed 的不重跑。
查询这一头还有:
- 关键词抽取缓存(cache_type=”keywords”):同一个 query 不重复抽关键词。
- 查询响应缓存(cache_type=”query”,可选):默认关闭,开了之后同一个 query 命中过的话直接复用上一次 LLM 生成的回答。
这套缓存层在调试阶段的收益非常大。我自己的 LightRAG 项目里,kv_store_llm_response_cache.json 经常涨到几百兆——但每次帮我省下大笔 API 费用的时候,那点磁盘代价完全值得。
索引这条流水线就拆到这里。下一篇我们聊存储层——三种 base storage 怎么设计接口、JSON 和 PostgreSQL 和 Neo4j 各自的取舍、生产环境怎么选。
上一篇:理解四种查询模式——local、global、hybrid、naive 和 mix
本文由 AgentPlanFlow 生成